《霓虹深渊的积木密语》-全面理解大模型Token
霓虹流影逐丝弦,字海寻踪积木悬。
谁解数字接龙意,半是神机半是缘。
巷口的占卜摊
雨丝把新上海的霓虹泡得发软,青橙色的光顺着摩天楼的玻璃往下淌,在弄堂口积成一滩会变色的水洼。阿明蹲在水洼边,第三次把那串打了三个叉的聊天记录甩到光脑屏上:
“见鬼了,我问它‘犇字怎么读,什么意思’,它前半句说读bēn,是三头牛的意思,后半句给我扯到‘牛年大吉’的祝福语?还有上次让它数我写的文案里有几个‘的’,数三遍三个结果,这人工智能怕不是个傻子?”
蹲在他对面的陈叔叼着半根电子烟,烟圈里飘着淡蓝色的数据流。这老头是弄堂里有名的“模型裁缝”,靠给各家大模型调提示词吃饭,他把手里的银灰色小盒子往台阶上一放,盒盖弹开,里面是五颜六色刻着奇怪纹路的积木块。
“傻?它看你说的话,跟你看乱码差不多。你以为你在跟它说话,其实你们俩中间隔了个翻译官,名字叫Token。”
积木的秘密
阿明刚要问什么是Token,陈叔伸手敲了敲他的光脑:“把你刚才那句话‘我爱吃苹果’输进去。”
屏幕上跳出字的瞬间,盒子里唰地跳出四块积木:一块刻着“我”,一块刻着“爱”,一块刻着“吃”,最后一块刻着“苹果”,每块积木的底部都印着一串数字:102、394、572、4198。
“看见没?这就是大模型眼里的字。你说的每一句话,它一个字都看不懂,只会先拆成这样的小积木,每个积木对应一个固定的编号——这就是Token,它手里唯一能玩的东西。”
陈叔伸手拨了拨那四块积木:“你以为它是在‘写回答’?它根本就是在玩数字接龙。看见前面这串编号102、394、572、4198,它从自己脑子里几亿条数据里找,下一个最可能接的数字是啥,找到数字,再对应回积木上的字,拼起来给你看。”
他又输入“犇”字,这次盒子里跳出来三块一模一样的积木,每块都刻着“牛”,编号都是2156。
“为啥它知道犇和牛有关?这字太偏了,它的积木盒里没单独的‘犇’,就直接拆成三个‘牛’的Token,看见三块牛,自然就往牛的意思上猜。要是你用整词当单位,这世界上的生僻字、外来词、错别字加起来比天上的星星还多,它的积木盒得装得下整个宇宙才行?有了Token就简单了,只要几万块积木,就能拼出所有语言的所有话,中文英文韩文,哪怕是火星文,拆成块都能认。”
被遗忘的旧梦
阿明听得愣神,突然想起上周的事:“怪不得我上次把三十页的合同拍给它,让它帮我改,它改到后面就乱了,前面说要改的条款全忘了,我还以为它记性差。”
陈叔嗤笑一声,从盒子里摸出个小小的电子计数器,上面跳着数字:“什么记性差,是它的口袋装不下了。你常看见的‘32K上下文’,说的不是能装32000个字,是能装32768块Token积木。你输入的合同,前面的聊天记录,再加它要写的回答,所有积木都得塞这个口袋里。口袋满了怎么办?只能把最早放进去的积木扔了,自然就忘了你最开始说的啥。”
他指尖在计数器上点了点,数字跳了两下:“还有你天天喊的API收费贵,那也是按Token算钱的。上次隔壁公司那小子,写个提示词啰啰嗦嗦三百字,拆出来四百多块Token,后来我帮他改成一百字不到,拆出来才一百二十块,费用直接少了三分之二,效果还更好。”
阿明突然想起之前数“的”字的事,脱口而出:“那它数不对字,也是因为这个?”
“可不嘛。”陈叔把“的的的”三个字输进去,盒子里跳出来三块一模一样的Token,编号都是101,“它眼里只有编号,哪看得见你写的字?你问它有几个‘的’,它得先回忆这几个编号对应的是‘的’,再数有几个,哪像你一眼扫过去就知道是三个。偶尔数错太正常了。”
尾声
雨停的时候,阿明抱着那盒积木走出弄堂,远处的霓虹把他的影子拉得很长。他第一次觉得那些屏幕上跳出来的文字不是冷冰冰的,背后是无数个小小的积木块,在数字的海洋里一块一块往下接,接成一句句能听懂的话。
陈叔站在巷口抽烟,看着男孩的背影消失在人流里,烟圈里飘着四个编号:102、394、572、4198。
原来人和机器最遥远的距离,从来不是有没有灵魂,是你看见的是一句“我爱你”,它看见的是三个数字。而那些数字拼成的温度,其实和人类写在纸上的字,没什么两样。
【收尾诗】
数海浮游积木轻,千言万语块中生。
须知字里相逢意,半是人工半是程。
知识坐标
- • 大模型处理语言的最小单位(Token)
- • 大语言模型的文本切分机制(分词/子词切分)
- • 大模型的生成逻辑(自回归预测/下一词预测)
- • 上下文窗口的计算依据(Token计数限制)
- • 大模型API的计费规则(按Token消耗量收费)
- • 大模型对文字计数不准确的底层原因(基于Token而非原始字符处理)
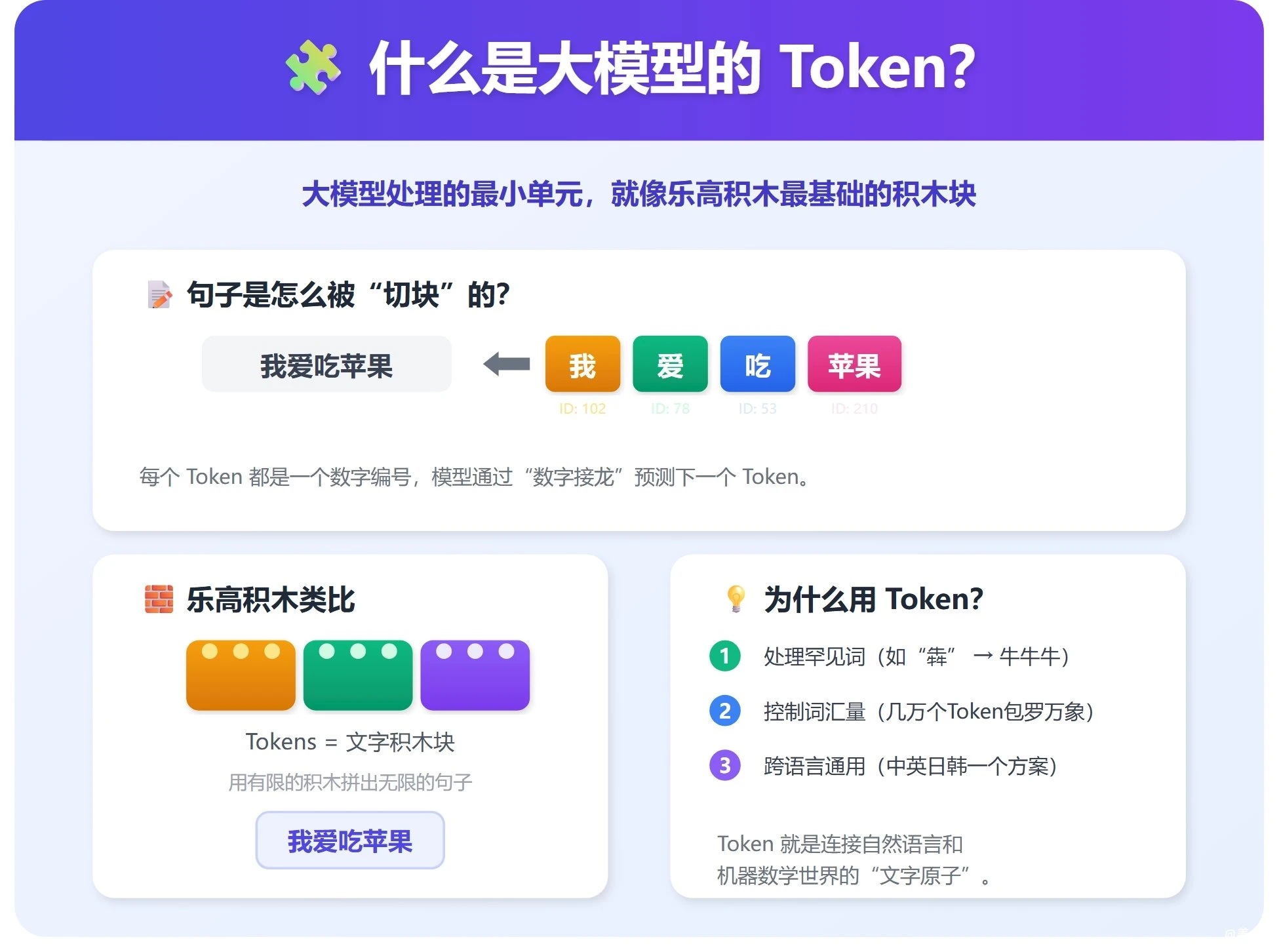
我们平时和聊天机器人对话,感觉是在“写字”或“说话”,但大模型其实看不懂原始的文字。它处理的最小单元就叫 Token。
你可以这样理解:
如果把大模型想象成一个用乐高积木搭东西的机器人,那 Token 就是它手里最基础的积木块。 我们给它的每句话,都会被拆成一堆编号的小积木;它回答时,再把这些积木拼回我们能看懂的文字。
一个直观的例子:句子是怎么被切块的?
不同模型的切分习惯不同,但原理相似。比如“我爱吃苹果”这句话:
- • 一种切法(偏字): “我” / “爱” / “吃” / “苹” / “果” (5个Token)
- • 另一种切法(偏词): “我” / “爱” / “吃” / “苹果” (4个Token)
- • 英文例子:“I love apples.” 可能会被切成 “I” / “ love” / “ apples” / “.” (注意空格也算在Token里)
最核心的一点: 对于模型来说,每个Token背后其实就是一个数字编号。大模型本质上是在做一种海量数据训练出来的“数字接龙”游戏——它根据前面的数字序列,预测下一个最可能出现的数字是几,再把数字还原成文字。
为什么用Token,而不是直接用字或词?
这主要为了解决几个问题:
- • 处理生僻词和拼写错误:“犇”这个字不常见,模型可能不认识“犇”这个词,但认识“牛”、“牛”、“牛”这三个Token,所以它能把“犇”拆成三个“牛”来处理,大概猜到和牛有关。
- • 控制词汇量:如果以词为单位,世界上所有语言的所有词组合起来是天文数字。而以Token(比如常用的子词)为单位,一个模型只需要掌握几万个Token,就能拼出无穷无尽的句子。
- • 跨语言通用:这种切块方式对中、英、日、韩等不同语言一视同仁,一套切分逻辑就能处理多语言混合的文本。
明白了Token有什么用?
这对你使用大模型有非常实际的意义:
- 1. 决定了模型的“上下文长度”
模型不是看字数,而是看Token数。比如某模型支持“32K上下文”,意思是一次最多能处理32768个Token。你输入的提示词和聊天历史,加上模型即将生成的回答,全都得塞进这个限制里。一旦超了,模型就会“忘记”最早说的话。 - 2. 是计算费用的直接依据
几乎所有大模型的API接口,都是按Token数量收费的。你用同样的意思提问,不同的措辞,消耗的Token数和花的钱可能差好几倍。 - 3. 解释了为什么模型有时会“变笨”
如果你让模型“数一下回答里有几个‘的’字”,它有时会数错。因为它看到的是Token的编号,而不是原始文字,它对字数的感知是通过Token间接建立的,不如人类直接看字那么精准。
简单说,Token就是大模型眼中的“文字原子”,是连接我们人类自然语言和机器数学世界的桥梁。
