史上不怎么全的Ollama+AnythingLLM部署及使用
1.下载及安装Ollama
Ollama的官网为:https://ollama.com/,点击右上角的Download即可下载模型。注意下载模型时根据自己电脑的配置情况下载。
Ollama支持macOS、Linux和Windows版本,下载后按照提示进行安装即可。

2. 下载预训练好的大语言模型
(1)打开Ollama官网后,点击Models菜单,根据需要下载需要的开源大模型。
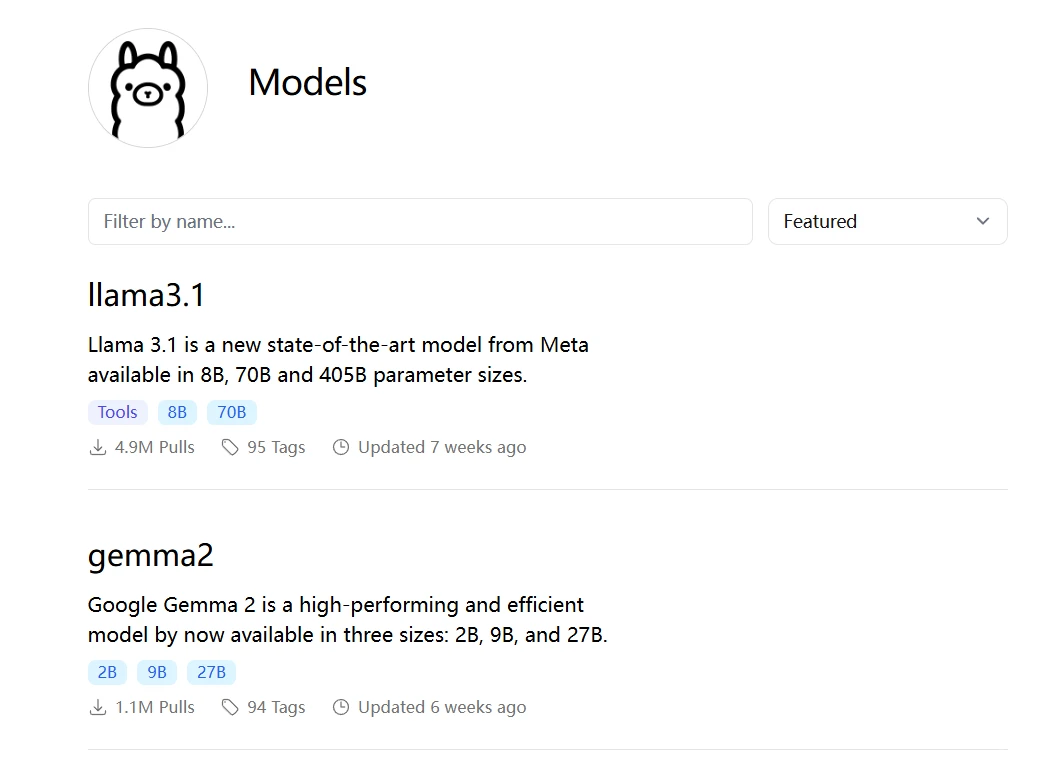
(2)查看大模型的介绍信息
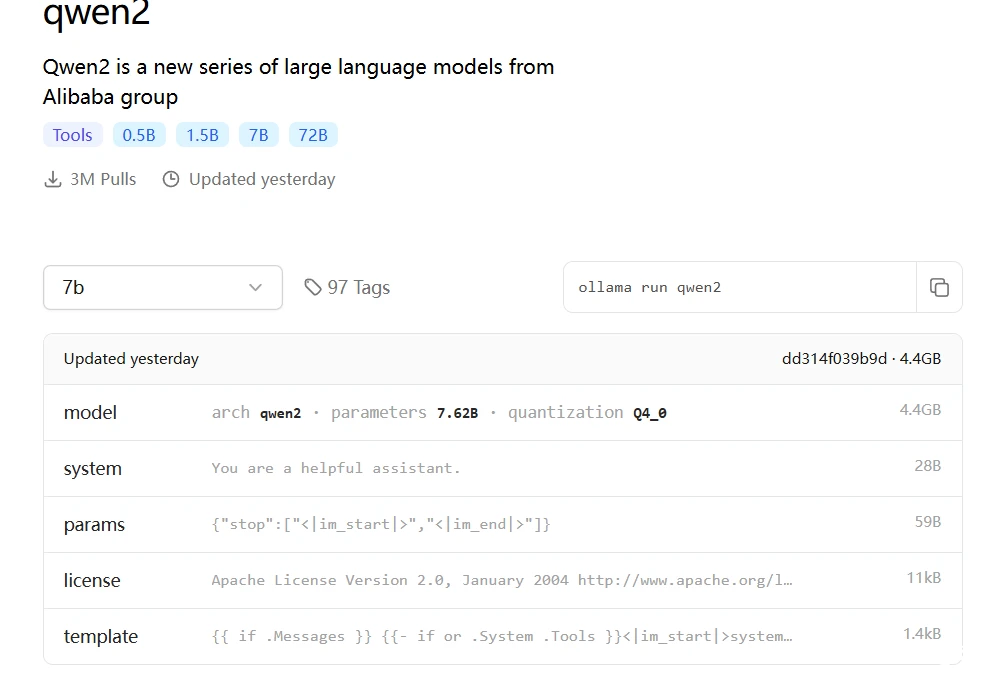
点击需要下载的大模型,进入大模型的详细介绍页面,包括大模型的参数量、大小、回复模板、问答表现等详细信息。
3. 本地命令行运行大模型
(1)下载好预训练的大模型后,打开电脑终端,在终端内输入 ollama run 大模型名 即可运行大模型。

运行之后即可在命令行中输入你的问题,此时会调用本地大模型进行回答。
(2)如果不知道大模型的名称,可以输入ollama list 查看已安装好的大模型

(3)ollama也可以采用服务的方式运行,具体命令为: ollama serve
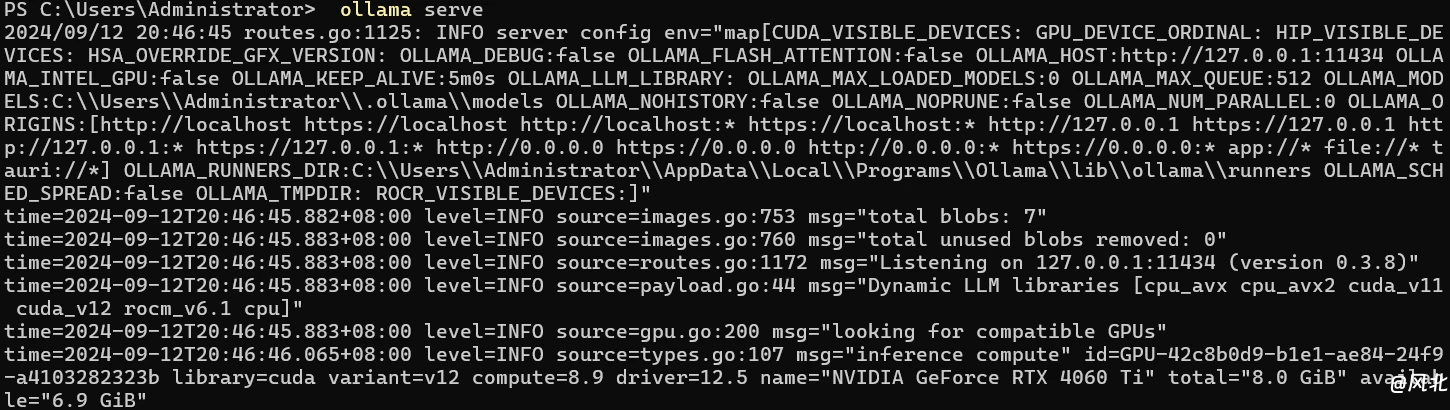
4. ollama大模型本地API调用
除了在命令行中使用外,ollama还开放了大模型的API调用功能,具体方法如下:
(1)查看API调用地址
命令行执行ollama show --help 即可获取本地API调用接口,如本地的地址为:http://127.0.0.1:11434/

(2)调用API开展对话
① generate方法:该方法可以流式返回结果,具体用法如下:
curl http://localhost:11434/api/generate -d '{
"model": "qwen2:latest",
"prompt":"GIS的全称是什么"
}'如果不想流式返回,想要一次性返回结果则需要添加参数:"stream": false
curl http://localhost:11434/api/generate -d '{
"model": "gemma:2b",
"prompt":"GIS的全称是什么",
"stream": false
}'② chat方法:对话方式
curl http://localhost:11434/api/chat -d '{
"model": "gemma:2b",
"messages": [
{ "role": "user", "content": "GIS的全称是什么" }
],
"stream": false
}'generate 和 chat 的区别在于,generate 是一次性生成的数据。chat 可以附加历史记录,多轮对话。
③ 也可采用Python进行调用
首先安装依赖库:
pip install ollama
pip install requests按照如下代码调用接口:
import ollama
import requests
host="127.0.0.1"
port="11434"
llm_model="qwen2:latest"
url = f"http://{host}:{port}/api/chat"
# 方式1:
client= ollama.Client(host=url)
res=client.chat(model=llm_model,messages=[{"role": "user","content": "SAM是什么"}],options={"temperature":0})
print(res)
#方式2:
headers = {"Content-Type": "application/json"}
data = {
"model": llm_model, #模型选择
"options": {
"temperature": 0. #为0表示不让模型自由发挥,输出结果相对较固定,>0的话,输出的结果会比较放飞自我
},
"stream": False, #流式输出
"messages": [{
"role": "system",
"content":"你能够将图片作为输入吗?"
}] #对话列表
}
response=requests.post(url,json=data,headers=headers,timeout=60)
res=response.json()
print(res)
方式2调用时需要开启ollama服务模式。
5. 基于Web UI的大模型调用
以上方法中,命令行方式较为局限,API需要做进一步的开发,因此目前也有基于ollama的相关Web UI应用可供选择,最常用的UI主要有:
open-webui:(openwebui.com)
AnythingLLM:AnythingLLM | The all-in-one AI application for everyone
如果仅是使用本地大模型,做一些本地的知识库,推荐使用AnythingLLM,较为简单,如果需要做一些UI的定制开发,建议使用Open WebUI。本教程以AnythingLLM为例介绍大模型的本地化构建方法。
6. 基于AnythingLLM的大模型应用
(1)运行本地大模型后,打开AnythingLLM,点击左下角的配置按钮![]() ,配置本地大模型。
,配置本地大模型。
(2)点击“AI Providers”菜单下的“LLM”菜单,根据实际情况按照如下配置。
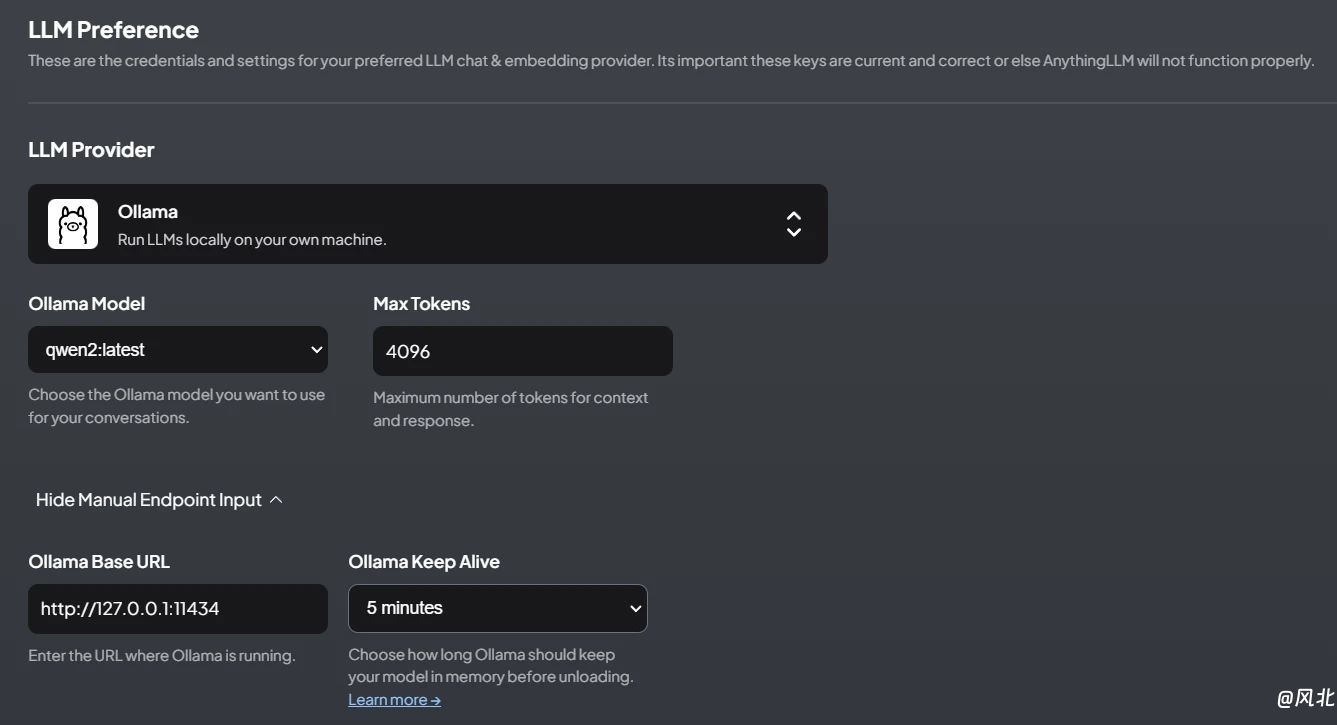
其中,LLM Provider选择Ollama,Ollama Model选择你实际安装的预训练好的大模型,其余一般无需改动。
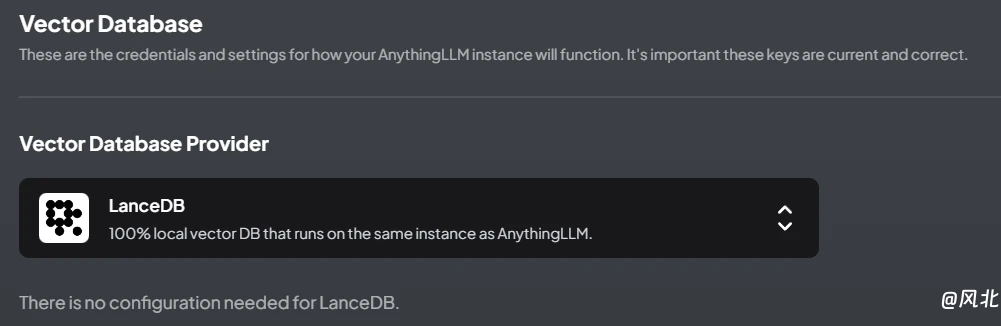
(3)设置向量数据库
点击“AI Providers”菜单下的“Vector Database”菜单,设置向量数据库,该向量数据库主要用于存储本地知识库,默认选择的向量数据库为“LanceDB”,适用于本地小批量数据库,较为简单,无需配置。
(4)设置嵌入词提供商
点击“AI Providers”菜单下的“Embedding Preference”菜单,设置嵌入词模型,默认为免费的“AnythingLLMEmbedder”,也可根据实际选择其它提供商。该设置主要用于处理上传的本地文档(如pdf文档)转换为词向量并存储到向量数据库中,主要用于构建知识库。
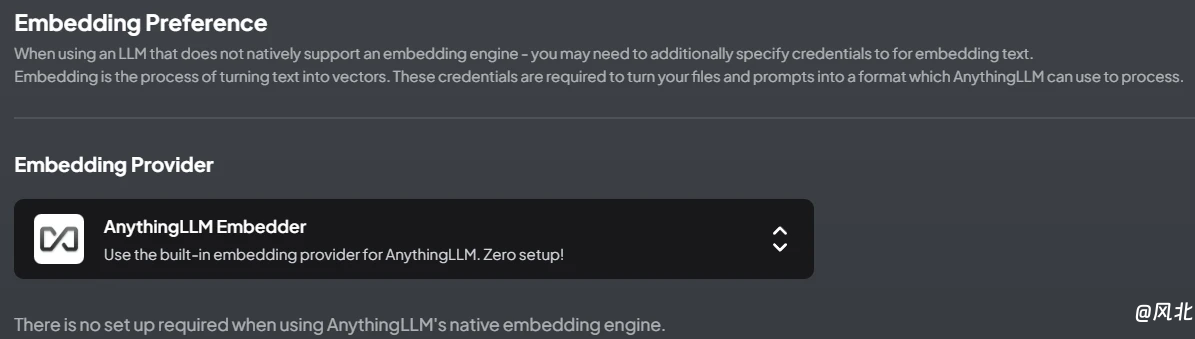
其余的默认设置即可。
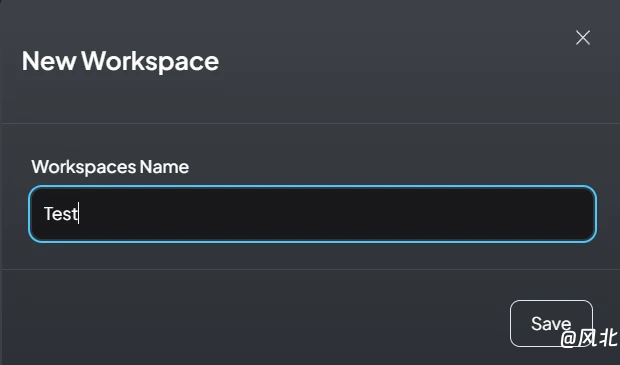
(5)开启本地会话
点击“+ New Workspace”按钮即可打开新的会话,然后就可以愉快的使用了。
(6)构建本地知识库
如果你想要本地的大模型更加懂你,能够为你提供更加符合你需求的内容,则可以添加本地的文件自动化构建知识库,文件可以是可编辑的文本、word、pdf等。
① 点击会话的 按钮,上传本地知识库。
按钮,上传本地知识库。
② 选择需要上传的文件,并加载到会话中
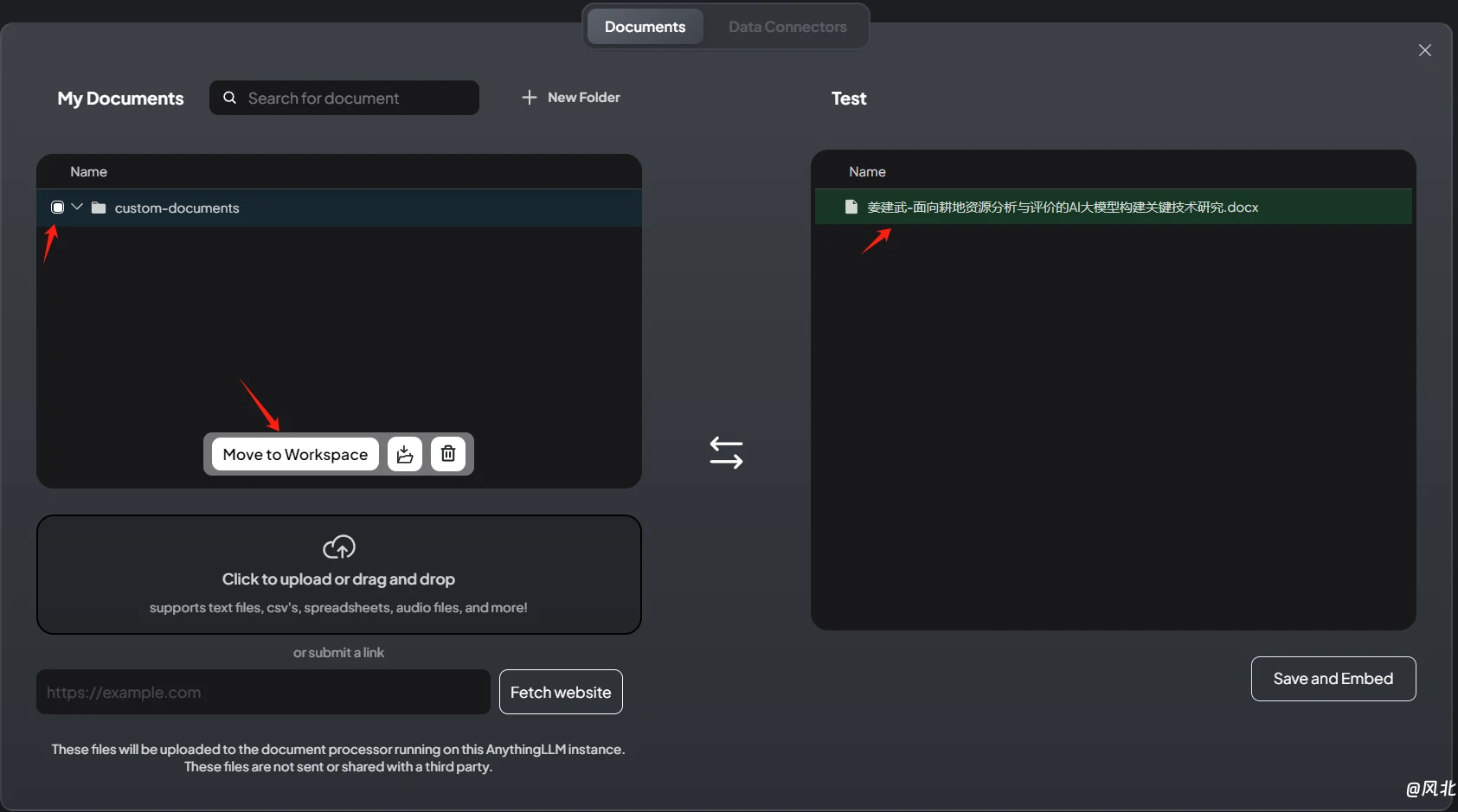
③ 点击右下角“Save and Embed”等待构建成功提示即可使用。

④ 调用本地知识库

==============
优雅的分割线啊
==============
以上是基于Ollama和AnythingLLM构建本地大模型的示例,后续还会继续就大模型相关内容进行更新,TODO List如下:
 多模态数据信息提取方法
多模态数据信息提取方法
RAG本地大模型知识库构建教程
提示词工程
定制化WebUI开发教程
