Python应用程序调优
最近在做一些深度学习、关联规则挖掘相关的算法,其中运行时间和占用内存是算法好坏的评价标准之二,在算法实现过程中踩了一些坑,也误打误撞找到了一些解决办法,将其发布于本博客,本博客将持续更新!!!
1 时间调优
1.1 不要在程序内部频繁使用垃圾回收函数 gc.collect(),这将使程序的运行时间慢100倍
# 示例程序
start = time.time()
lines = ['X1','X2','X3','X4','X5','X6','X7']
line = ['X3','X5','X7']
for ln in lines:
if ln in line:
ln = ln
del lines, line
gc.collect()
end = time.time()
print("使用垃圾回收: %sS"%(end-start))

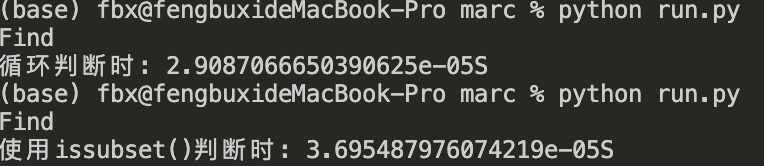
1.2 判断一个列表是否在另一个列表中时直接用循环代替issubset()
# 示例程序
start = time.time()
lines = ['X1','X2','X3','X4','X5','X6','X7']
line = ['X3','X5','X7']
flag = True
for ln in line:
if ln not in lines:
flag = False
break
if flag:
print('Find')
end = time.time()
print("循环判断时: %sS"%(end-start))
start = time.time()
lines = ['X1','X2','X3','X4','X5','X6','X7']
line = ['X3','X5','X7']
if set(line).issubset(set(lines)):
print('Find')
end = time.time()
print("使用issubset()判断时: %sS"%(end-start))
1.3 采用itertools函数生成全排列时使用combinations()不要使用product(),后者比前者慢100倍
# 示例程序
line = ['X10', 'X9', 'X2', 'X6', 'X4', 'X5']
count = len(line)
lines = []
s = time.time()
for i in range(2,count):
lines.append(list(combinations(line, i)))
e = time.time()
print('Combinations:{:f}'.format(e-s))
s = time.time()
for i in range(2,count):
lines.append(list(product(line, repeat=i)))
e = time.time()
print('Product:{:f}'.format(e-s))

未完待续......
2. 内存调优
未完待续......
阅读剩余
版权声明:
作者:姜九二
链接:https://www.jiangjianwu.cn/development/coding/python/492/python%e5%ba%94%e7%94%a8%e7%a8%8b%e5%ba%8f%e8%b0%83%e4%bc%98.html
文章版权归作者所有,未经允许请勿转载。
THE END
