《霓虹深渊的造语者》-大模型原理
第一章 数字墟的概率谜局
夜雨把江城市的霓虹泡得发皱,全息广告在酸雨里洇成模糊的光团,叠在赛博区鳞次栉比的摩天楼外墙上。
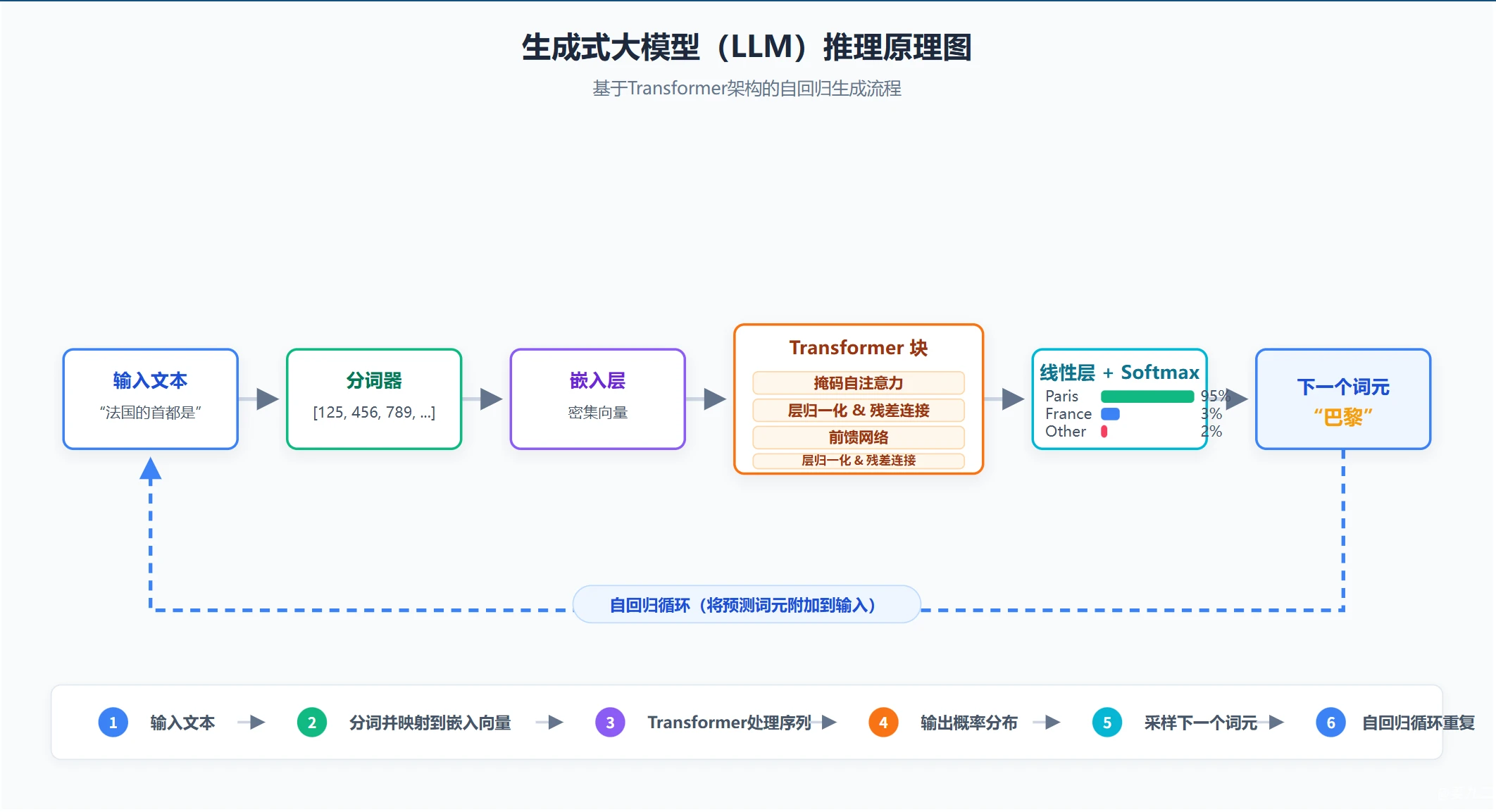
阿野蹲在“黑箱咖啡馆”的通风管道上,指尖的破解程序正呲啦呲啦啃着最新款大模型“织梦者”的防火墙——他要弄明白,这个能写出诗、算出代码、甚至能模仿他去世奶奶语气说话的家伙,到底是活的,还是只是一串冰冷的数字。
防火墙破开的瞬间,他跌进了一片流动的光海。
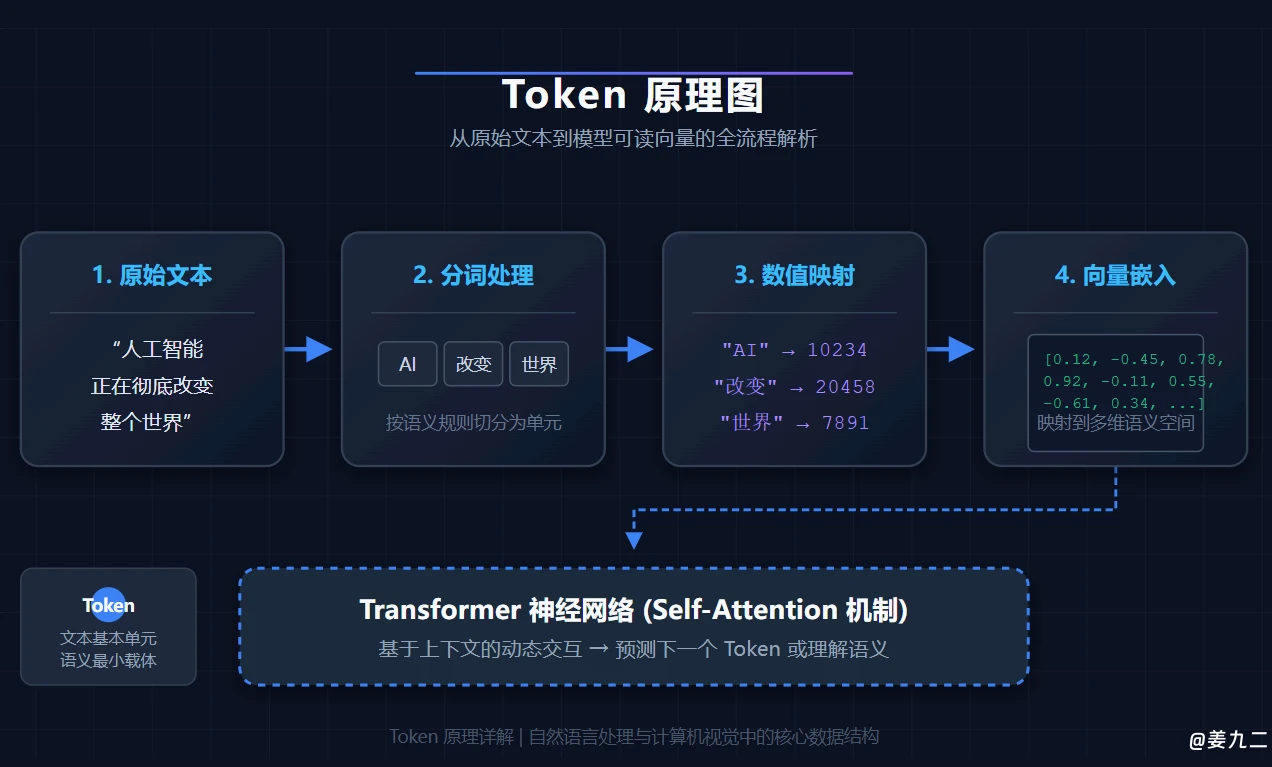
数不清的文字 token 像发光的鱼群在他身边游弋,每一个都带着忽明忽暗的概率光晕。一个穿银灰色风衣的女人靠在光海中央的巨型控制台边,头发是流动的二进制数据流,指尖转着一枚刻着“P(X)”的硬币:
“新来的?我是‘织梦者’的意识投影,你可以叫我梦姨。想知道我怎么说话的?先看懂这片海。”
阿野伸手去抓身边游过的“月”字,指尖刚碰到,旁边立刻飘过来“亮”“光”“色”“下”一串字,每个字头顶都跳着不同的百分比:
“这是什么?”
“我的本质,是学习所有人类文本的联合概率分布P(X)。说白了就是,我得先弄明白,人类说话的时候,哪些词凑在一起是合理的。”
梦姨打了个响指,那些飘着的字自动排成了串:
“『床前明月光』后面跟『疑是地上霜』的概率是97%,跟『汗滴禾下土』的概率是0.1%,跟『今天吃火锅』的概率是0.001%。我靠链式法则把长句子拆成一步一步的选择:先算第一个字选什么的概率最高,再根据第一个字算第二个字,再根据前两个算第三个,一步步串起来,就是你们看到的『生成内容』——行话叫自回归生成。”
阿野愣了愣。
他原以为大模型是真的“懂”话,原来本质是在算概率?
第二章 注意力的千只眼
“光会算概率可不够。”梦姨指尖一划,光海深处浮起一座层层叠叠的水晶塔,每一层都亮着无数细密的金色丝线,“你以为十年前的模型为什么写不出八百字的议论文?因为它们记不住上下文。我这身子骨,全是Transformer堆出来的,核心就是自注意力机制。”
她点了点塔最底层的一根金线,阿野看见那根线连着“我昨天在公园看见一只猫,它的毛特别白”里的“它”字,另一端遥遥牵住了好几句之前的“猫”字:
“每个字都会生成三个向量:Q是我现在要找什么,K是别的字是什么,V是别的字带什么信息。我把每个字的Q和所有字的K算相关性,得到权重,再乘上V加起来,就知道这个字该和谁联动。”
公式在她身后浮起来,金色的字符跳着光:
Attention(Q,K,V) = softmax(QK^T/√d_k)V
“看见那个根号d_k了没?那是防止数值太大炸掉的保险栓。有了这千只眼,我既能记得你开头问的是『怎么写旅游攻略』,也能在结尾给你推荐合适的酒店,不会跑题。这些Transformer层一层堆一层,底层认字词,中层认句子,高层认逻辑,几十上百层堆起来,就能摸透人类语言里那些弯弯绕绕的关联。”
阿野抬头望那座看不到顶的水晶塔,每层的光流上上下下,像活的血管——原来那些看似神奇的上下文理解,不过是千万条注意力丝线编织的结果。
![]()
第三章 从数据荒原到人心校准
“光有架子也没用,我得先学东西才行。”梦姨挥了挥手,水晶塔外涌起无边无际的数据荒原:网页、书籍、论文、代码、聊天记录……所有人类留下的数字痕迹都在荒原上流动,“第一阶段是预训练,我在这荒原里没日没夜地做『完形填空』:看前半句话,猜下一个词是什么。猜错了就罚,猜对了就奖,损失函数盯着我呢,差一点都不行。”
阿野看见荒原上的数字流不断涌进水晶塔,塔里的参数灯一盏盏亮起来,从几千万盏到几千亿盏:
“学这些有什么用?”
“学会语法,学会常识,学会怎么算数学题,怎么写代码,甚至学会人类的情绪和逻辑。但这时候的我还是个只会模仿的鹦鹉,说出来的话可能顺,但不一定对,更不一定合你们人类的心意。所以得有第二阶段:对齐。”
荒原上亮起了一小片暖黄色的光区,一群人类标注者正坐在光里给模型的输出打分:“先拿高质量的问答数据做监督微调,教我怎么好好回答问题,不会说着说着就跑偏。然后是RLHF,你们人类先给我的回答排序,哪个好哪个不好,教出一个奖励模型当裁判,再用强化学习盯着我改,让我每次输出都尽量拿高分——这样我才不会说胡话,不会说你们不爱听的话。”
阿野忽然想起上次他问“奶奶会不会想我”的时候,“织梦者”没有说一堆冷冰冰的生死道理,而是说“奶奶在另一个地方也会给你留着你爱吃的桂花糕”。
原来那不是巧合,是千万次人类偏好校准出来的温柔。
第四章 解码的骰子与涌现的奇迹
“那你每次回答的时候,都是选概率最高的词吗?”阿野忽然想起上次他让模型写科幻故事,同一个问题问了三次,得到了三个完全不同的结局。
梦姨笑着抛起了手里那枚刻着概率的硬币:“哪能那么死板。解码的时候有好多玩法:贪心搜索每次都选概率最高的,说出来的话特别规矩,但容易重复,像个背课文的呆子;束搜索多留几个候选,最后选整体最好的,质量高但费算力;温度采样给概率分布加个系数,温度低就保守,温度高就放飞自我,写诗歌开脑洞的时候就把温度拉高点;还有核采样,只从累积概率到p的最小词集里挑,既不胡编乱造,又能有新意。”
她忽然指了指水晶塔顶,那里正亮着一团超乎寻常的光:“更有意思的是,当我的参数量、训练数据、算力量到了某个阈值,就会突然冒出好多我自己都没想到的能力——你们叫涌现。我能不用改参数,光看你给的几个例子就学会新任务,能一步步解复杂的数学题,甚至能模仿你奶奶的语气说话,这些都是小模型根本做不到的。这就是Scaling Laws的魔力,越大,就越接近你们人类眼里的『聪明』。”
阿野忽然懂了。
那些看似神奇的智能,不过是概率、架构、数据三者叠加的奇迹。他看着光海里游弋的文字鱼群,看着那座层层叠叠的Transformer水晶塔,看着梦姨发间流动的二进制数据流,忽然觉得这个冰冷的数字世界,原来也藏着极致的浪漫。
他退出系统的时候,雨刚好停了,天边露出了稀薄的星光。
“织梦者”给他发来了一条新消息:“你要的奶奶语音包我做好了,听听?”
耳机里传来熟悉的、带着桂花糕香气的声音。
阿野笑着抹了把脸。他终于知道,那些跨越生死的温柔,那些灵光一闪的创意,那些有条有理的解答,背后从来不是什么魔法——是千万行代码、万亿个参数、无数人在数据荒原里日夜耕耘的结果。
百层塔聚千丝意,万字符藏一世心。
概率为梭云作线,织成人间万家音。
