一种网络爬虫的页面列表信息自动提取方法及系统(202010222132.4)
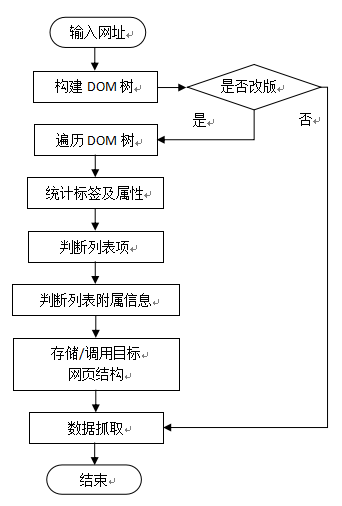
本发明涉及一种在网络爬虫技术中智能识别网页列表中列表项(标题)和列表项附属信息(属性,如时间、发布者等)的自动提取算法。通过分析网页列表页的结构、分析列表页HTML标签的排列特点,推断页面中列表项和列表项属性所在的位置,实现网络爬虫自动抓取网页内容的目的。属于网络爬虫技术应用领域。
阅读剩余
版权声明:
作者:姜九二
链接:https://www.jiangjianwu.cn/research/1040/%e4%b8%80%e7%a7%8d%e7%bd%91%e7%bb%9c%e7%88%ac%e8%99%ab%e7%9a%84%e9%a1%b5%e9%9d%a2%e5%88%97%e8%a1%a8%e4%bf%a1%e6%81%af%e8%87%aa%e5%8a%a8%e6%8f%90%e5%8f%96%e6%96%b9%e6%b3%95%e5%8f%8a%e7%b3%bb%e7%bb%9f2.html
文章版权归作者所有,未经允许请勿转载。
THE END
